
If you are not tech-savvy, canonical tag SEO may sound complicated and outlandish to you. However, it is an important tool in your search engine optimization arsenal and irreplaceable when managing duplicate content. By understanding what purpose canonicals serve and how to use them properly, you can optimize your pages better and maintain link equity.
As with any other aspect of SEO, there are many speculations surrounding what canonicals can and can’t do, and how they should be used. Since these types of tags have been around for over a decade now, there’s a lot of outdated and misleading information circulating on the internet.
So in this article, we talk about everything you need to know about canonical tag SEO in 2022. Read on and take notes!
What Are Canonical Tags?
Canonical tags are pieces of code that can be put in the head section of a page’s HTML. They are used when a website has URLs with identical, similar, or closely related content, and serve to notify search engines which one is the most important.
Canonical link tags look the following way:
<link rel=”canonical” href=”https://example.com/text/text-text” />
The link inside the tag is the URL of the main page and, according to Google’s regulations, should be an absolute URL and not a relative one. This means that you have to use the full address of the page, including the protocol, the domain, and the location of the content in your website:
<link rel=”canonical” href=”https://example.com/text/text-text” />
instead of
<link rel=”canonical” href=”text/text-text” />

What Types of Pages Need Canonical Tags?
Even if you don’t have obviously duplicate content such as repeating pages, you may still have duplicate URLs that can confuse the bots, and, potentially, result in indexing setbacks. These may be created by your content management system (CMS), caused by an inconsistency in the way you use pathways, protocol issues, and so on.
So let’s have a look at the types of pages that can benefit from canonical tag SEO, and how to proceed in each case:
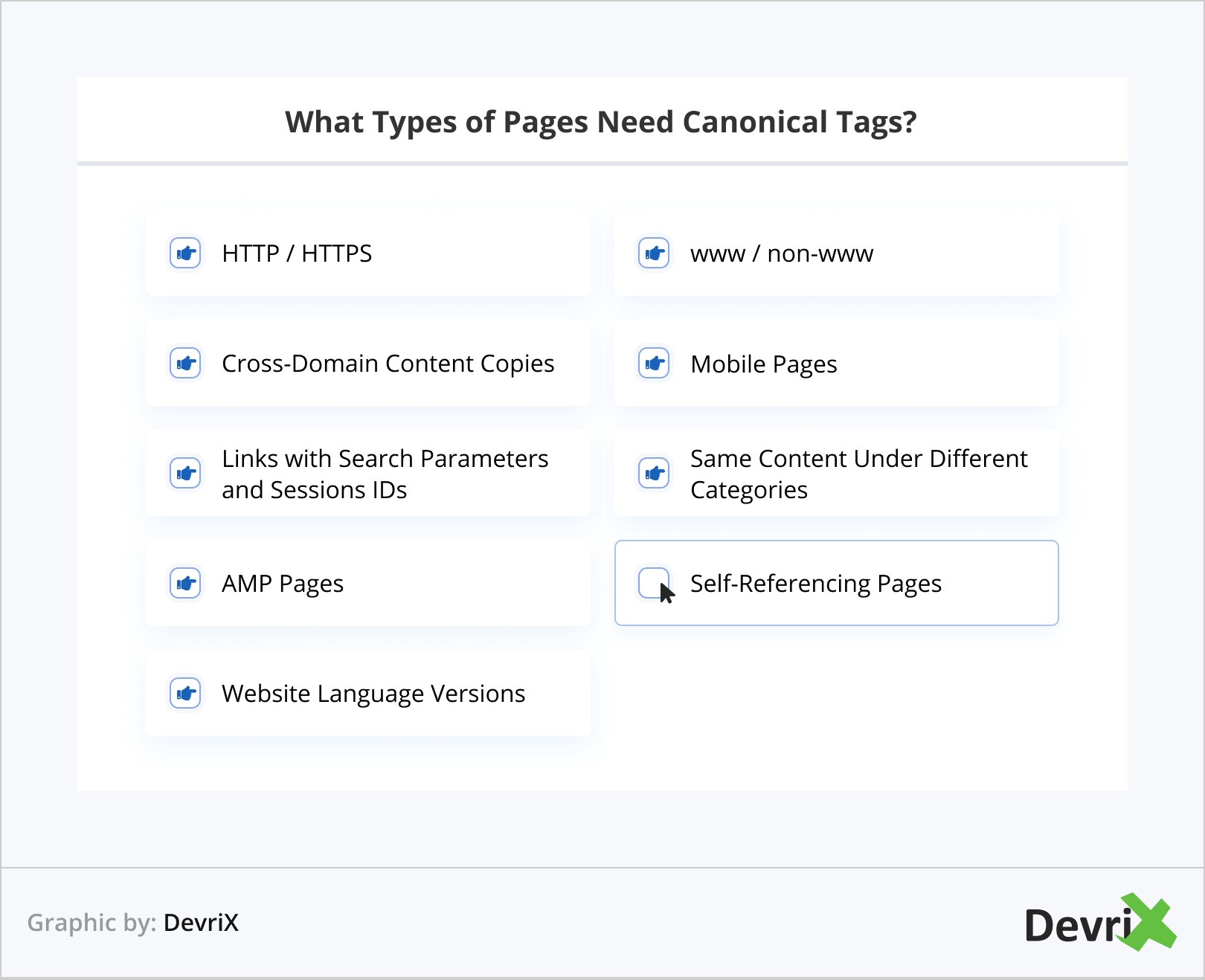
HTTP / HTTPS
Google prioritizes HTTPS protocol, so, by default, if you have a page with both HTTP and HTTPS version, and no redirect from the former to the latter, the bot will show the HTTPS version as canonical. If you don’t want to use a 301 redirect and discard the HTTP version altogether, you should add a canonical tag to the HTTPS.
However, if, for some reason, you want to mark the HTTP version as the more important one, you can add the canonical tag to it. Keep in mind, though, that Google may still choose to show the secure version, despite your recommendations.
www / non-www
For the bots, https://www.example.com/text and https://example.com/text are not one and the same thing. Ideally, you should be consistent in using a www or non-www version of your links.
However, you can’t be sure what your visitors may key in search engines and browsers, and what they might bookmark. Canonicalizing one of the versions will ensure that the bots know which one you prefer, and may focus on it.
Cross-Domain Content Copies
If you syndicalize content, as digital publishers often do, or want to publish a piece on multiple domains, you should canonicalize the original page (the one on your own website).
This can be done by adding the rel=”canonical” tag to your page and asking publishers to add it to their page’s code with a link to the original. This way, all the link juice and equity will be channeled to your website.
Furthermore, the bots encounter the same content on multiple locations, they won’t be confused as to which link to rank higher.
Mobile Pages
If your website is not responsive and you have a stand-alone mobile version, Google views the desktop and the mobile URLs as separate pages:
https://m.example.com/text ≠ https://example.com/text
To avoid confusion and prevent distributing authority between the two, you should set only one of them as canonical. With mobile-first indexing in place, it’s best to canonicalize the mobile page.
However, you shouldn’t worry – if the user keys a query on desktop, the bots will show the appropriate version despite the tag.
AMP Pages
When you have an AMP version of the content, the best practice is for the AMP page to be hosted on an address that is similar to the original one
https://example.com/news
https://amp.example.com/news
In this case, you should canonicalize the main page and add the canonical tag with the original link into the code of the AMP version. This way, the bots will identify more easily which one is the main page.
Links with Search Parameters and Sessions IDs
Session IDs and URL parameters often confuse bots and may result in them not managing to index your pages properly. If you can’t avoid using these, you should canonicalize the main page, so the bots know that the extensions in the link address are simply that and not a new page.
Parameters are most commonly used to better organize the content on eCommerce websites. They add values to the URL to indicate variations in the product such as color, size, and type, and can be used to apply various search filters, campaign tracking information, and so on.
Here’s how a page with parameters may look:
https//www.example.com/page?key1=value1&key2=value2
instead of
https//www.example.com/page
Session IDs can be used to track an individual user’s behavior on a website. For example, in an eCommerce store, the ID can be a cookie replacement that shows the website what pages the person visits. The information can be used so the person’s cart and last visited items are preserved until they leave the website.
Here’s how a page with a session ID may look:
https://example.com/index.jsp;jsessionid=07D3CCD4D9A6A9F3CF9CAD4F9A728F44
instead of
https//www.example.com/page
Ideally, the bots should be smart enough to recognize both parameters and session IDs. However, occasionally, they may become confused and this is why setting canonical tags will help them consolidate the pages’ rankings, instead of distributing them.
Same Content Under Different Categories
When you have the same piece of content under more than one category on your website, you have multiple URLs with almost the same content leading to the same page:
https://example.com/category1/text-text/
https://example.com/category2/text-text/
If you don’t mark up one of the pages as canonical and consistently link to it in your internal link building strategy, the bot will consider these as duplicates. It will not only waste time (and crawl budget) deciding which one to show to the user, but may even rank the two separately.
Self-Referencing Pages
Although it may sound redundant, self referencing is a thing, and has been confirmed by Google’s John Mueller to have SEO value in an answer to a user’s question on Reddit:

<link rel=”canonical” href=”b.html” /> If this is on a.html, then it’s just a normal canonical (technically canonical link element), if it’s on b.html, then it’s a self-referential one.
Since you don’t know how people link to your pages, a self-referential one helps to clean up small mistakes. For example, if a link goes to b.html?utm=cheese, then usually the server just shows b.html, and a self-referential canonical link element there would then encourage search engines to just use “b.html” instead of “b.html?utm=cheese”.
In a nutshell, the original page can and should also be tagged with a rel=canonical, so that it’s clearer to the bots that it is, indeed, the original.
Website Language Versions
If you have different language versions of your website, you may want to define as canonical only one of them. In this case, you can add the self-referencing rel=canonical tag to the code of the one you consider the main one, and point the other ones to it.
To make it easier for Google to understand why the two pages have similar or the same content but not duplicate, you should use the hreflang tag attributes. For example, if your website has versions in English UK, English US, and Spanish, you can add the following snippets to each respective version:
link rel=”alternate” href=”http://example.com” hreflang=”en-us” />
link rel=”alternate” href=”http://example.com” hreflang=”en-uk” />
link rel=”alternate” href=”http://example.com” hreflang=”en-es” />
and mark up the English US version as the canonical one.
However, keep in mind that, based on the user’s location, Google will have the last word on which page to show them, and may ignore your suggestion.
What Is Canonical Tag SEO Used for?
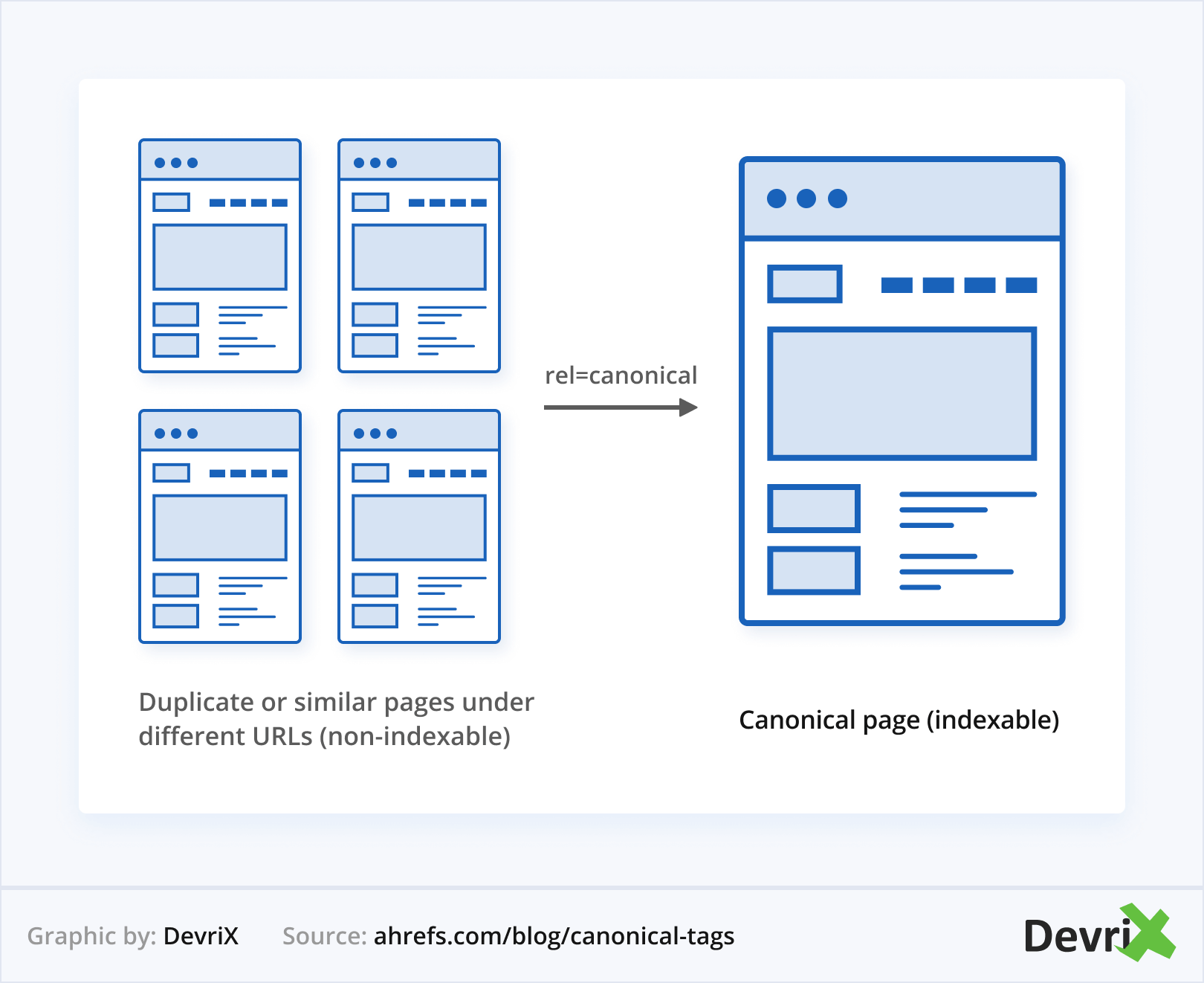
In a nutshell, the main purpose of canonical tag SEO is to manage duplication and preserve link equity. When, for one reason or the other, you have multiple URLs that lead to the same page, bots can become confused as to which URL to rank.
As a human, you see the links as, practically, the same thing. However, for the bot each URL has its meaning. If you don’t specify which one you consider to be more important, Google will make this choice for you. However, you and Google may have different priorities and different understanding of a link’s importance.
Furthermore, if you don’t specify which is the canonical path, each separate link will be served up to users in the search results under a different guise. This means that all the authority and link juice will leak out between the pages, instead of accumulating in only one of them.
Again, Google will decide to accept one of the pages as canonical, but if it doesn’t have instructions to refer to, theoretically, it could make a different decision each time.
Why You Shouldn’t Misuse Canonical Tags?
People should thread carefully with canonical tag SEO. If you try to manipulate the bots or misuse the tags for another reason (we’ll provide examples), you may end up confusing the crawlers and they may give up on indexing your links.
Furthermore, misplaced canonicals on large websites can drain your crawl budget. If the bots are not sure what’s going on with your pages, they will keep trying to figure it out, instead of crawling the new content that you have published. This will cause their work to lag, and affect your website’s performance in Google’s Search rankings.
In short, if you use canonicals the wrong way, you risk creating issues where they were none.
Common Misconceptions About Canonical Tags SEO
Here are the most common misconceptions about canonical tags in SEO. We’ve summarized it here for better clarity:
- Google Is Obligated to Comply with Them. False. Canonicals are recommendations and not rules. They serve as a way to suggest to Google which duplicate pages you consider to be the most important. However, even with these tags the bots may still decide that a different page is more suitable and choose it over the one you want
- They Are Used to Group Content By Topic. The only purpose of canonicals is to help bots sort out duplicate URLs. This means that if you have pages on similar topics, but target different keywords and have different content, canonical tags are not the right tool to unite their link equity. If two pages are widely different, but are connected with a rel=canonical, the bots will keep crawling them, trying to understand why the tag is there, and this will needlessly waste crawl budget.
- Canonical Tags Can Replace Redirects. Canonicalization does not have the same weight as redirects, because, as stated above, it’s not a directive, but a suggestion. So if you don’t want a page to be accessible or prioritized, the tag won’t help
- You Should Always Use Canonicals. Not necessarily. The goal here is to bypass technical issues that shouldn’t exist in the first place. If your URLs are consistent throughout your website, and you don’t have the issues we’ve talked about earlier, you may not need canonical tags. That said, if you are not sure, you may use the rel=canonical tag to self-reference only the pages that are most important to you, just in case.
How to Consolidate a Page as Canonical
Although Google always has the last word on what page it considers to be canonical, there are ways to strongly recommend the one that you prefer.
As people who have dealt with SEO know, Google uses various signals to decide how to crawl, understand, and index the web. If you use the right ones, it is more likely to listen to you.
In the case of canonicals, Google’s John Mueller says that the bots, indeed, try to read what the website wants them to do.
So how to tell Google what you want, aside from adding the rel=”canonical” link tag to your HTML header?
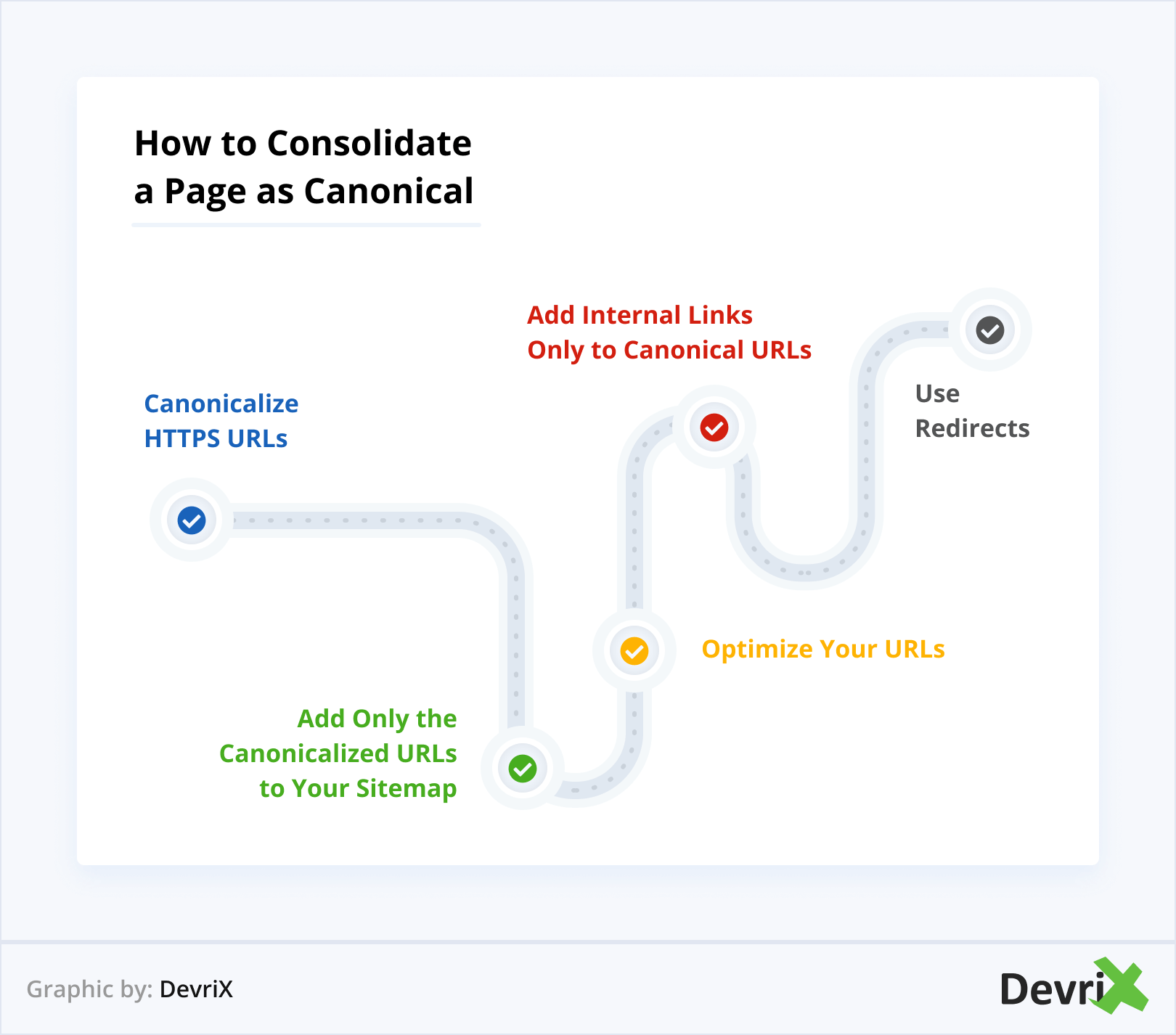
Canonicalize HTTPS URLs
Google strongly prefers HTTPS paths over HTTP ones, because they have the SSL (or TLS) certificates and offer a more secure transfer of information. So if your links use both types, Google will be drawn by the HTTPS one.
To avoid confusing the bots and making them choose between what they know is the right thing to do, and what you seem to be forcing them to do, it’s best to always canonicalize HTTPS links.
Add Only the Canonicalized URLs to Your Sitemap
The XML sitemap is an important tool in your SEO strategy and allows you to help bots prioritize and index your content. Google considers all URLs in the map as canonical by default because these are supposed to be your most important pages – the ones that you tell it to index.
So when you are creating your map, make sure to only add the pages that you consider as master-copies.
Optimize Your URLs
Bots also care about the way your URLs look. This means whether or not the user can easily make sense of them. Links with parameters that are confusing are more likely to be avoided since Google tends to choose what is shown in the SERPs. While it is possible for such a link to rank if it is a perfect match for the user’s query, it’s better to be safe than sorry.
Add Internal Links Only to Canonical URLs
Internal linking is a great way to show Google which links have more weight than others. When adding links to your articles, make sure that they are always canonicalized and point to the main URL. This way, the bots will know which pages are more important, and will consider them more relevant.
Use Redirects
When one of the duplicate pages is no longer of use to you, the best way to tell Google that you don’t want it crawled and indexed is to create a 301 server redirect. This way, instead of visiting both pages and having to choose, the bots will completely skip the outdated one in favor of the new one.
This is particularly recommended when you are installing SSL or TLS on your website and all your HTTP links become HTTPS. Creating redirects will ensure that anyone who has the old link bookmarked or backlinked will be automatically redirected to the new secure address. This will save the bots from having to make a decision themselves.
However, keep in mind that with redirects the old page becomes completely inaccessible to both Google and users. This is a drastic measure and should only be used if you really don’t need the page any more, but want to keep it’s equity. Also, too many redirects can, potentially, slow down your website.
Bottom Line
Canonical tag SEO is not complicated when you understand it and know how to use the proper tags.
What’s important to remember, is that the main purpose of the rel=canonical attributes is to manage URL duplication, and help bots figure out why different URLs point to similar content.
If you are not tech-savvy and need help managing the canonical SEO of your website, don’t hesitate to give us a call!
Team DevriX
This article is crafted by DevriX's seasoned marketing team, boasting over four decades of collective expertise in crafting sophisticated marketing funnels, devising comprehensive content frameworks and pillars, implementing engaging email campaigns, and creating impactful social media content designed for scalability.
Our marketing experts specialize in the complete spectrum of inbound marketing strategies. As an accredited HubSpot Agency Partner and a Semrush Partner, we engage in meticulous research, blending our extensive experience with the unique insights of our highly skilled team.
We set benchmarks in content creation by incorporating cutting-edge marketing trends, leveraging in-depth industry research, and utilizing state-of-the-art AI tools for data segmentation and captivating content hooks. Our proficiency extends across a diverse range of sectors, including working with SMEs, Fortune 1000 companies, global B2B brands, major publishing entities, WooCommerce platforms, business directories, and affiliate networks.



