
Duplicate WordPress pages are interpreted as a text or block of text that is an exact copy of original content that was found on another website. Copies that are paraphrased, even partly, or spun are also considered duplicate content. Websites that steal content from other pages usually do not rank well on search engines.
However, you can accidentally produce duplicate content on your own website. Pages that use the same wordings and have the same idea can be considered duplicate content. While Google doesn’t necessarily penalize websites for having duplicate content, it can negatively affect your search engine rankings. This can also have a negative effect on your website traffic.
Why Should Marketers Avoid Duplicate Content?
Just as we mentioned above, duplicate WordPress pages can cause issues with your search engine rankings. Some other problems that you might run into include the following:
- Your key pages might not show up on SERPs.
- Indexing problems might occur.
- Core site metrics such as traffic and rank positions will be affected.
- Link equity will be diluted.
- Your domain authority might be compromised.
Websites that have unique content are rewarded by search engines with higher rankings. As a result, marketers should regularly check their web pages for duplicate content to avoid confusing Google about which pages to rank higher.

The Two Types of Duplicate Content
Duplicate content can be divided into two: internal duplicate content and external duplicate content.
Internal duplicate content happens within your own website, which can be caused by having similar content on different web pages. Other causes of internal duplicate content problems include the following:
- On-page elements such as similar page titles, meta descriptions, and headings also classify as duplicate content. To avoid this, create unique variations that you can use for each page.
- Having the same product description for the items that you offer also counts as duplicate content. If you distribute your products to other resellers and third-party websites, then consider coming up with different product descriptions for each one. Alternatively, you can just include a summary and link it to your main page when providing the full details.
External duplicate content is when other webmasters copy your content and post it on their own websites. Here are the two main examples of external duplicate content:
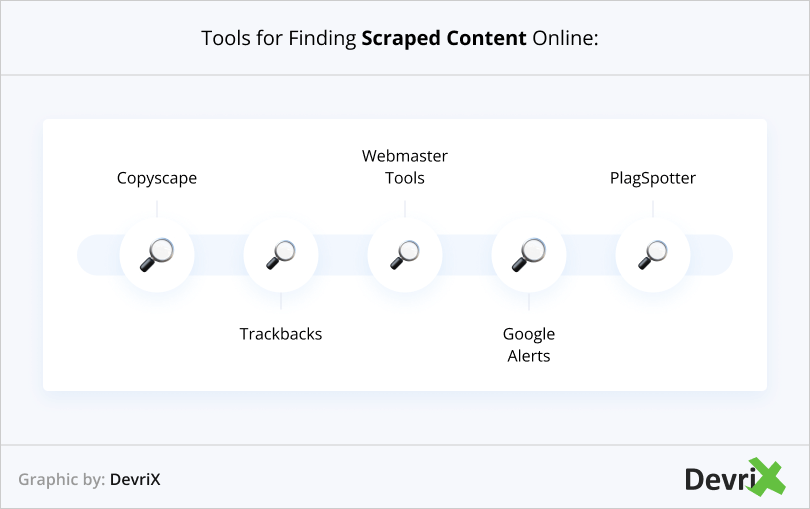
- Scraped content refers to stolen content copied by a webmaster from a website that is not their own. They usually have tools that they use to rephrase and spin the content that they’ve stolen and posted on their site. Most of the time, these “scrapers” don’t even bother replacing branded text in the content. You can search for scraped content and if you find some, then you can report it to Google to have it taken down.
- Syndicated content differs from scraped content in a way that allows your content to be published on another site. Different types of content including infographics, videos, and blog posts can be syndicated. To avoid content duplication, ask the third-party website owner if they can just syndicate the headline and then put a link to your website to view the entirety of the content. Tweak the headline and make sure that it’s not similar to the one you are using on your page. However, there is a plus side to content syndication, in which the original content creator gets the chance to have free publicity and backlinks to their website.
How Can I Scour the Internet for Duplicate Content?
First, check if you have specific web pages that are ranking low on search engines. Next, take the steps below to see if your content has been copied somewhere else:
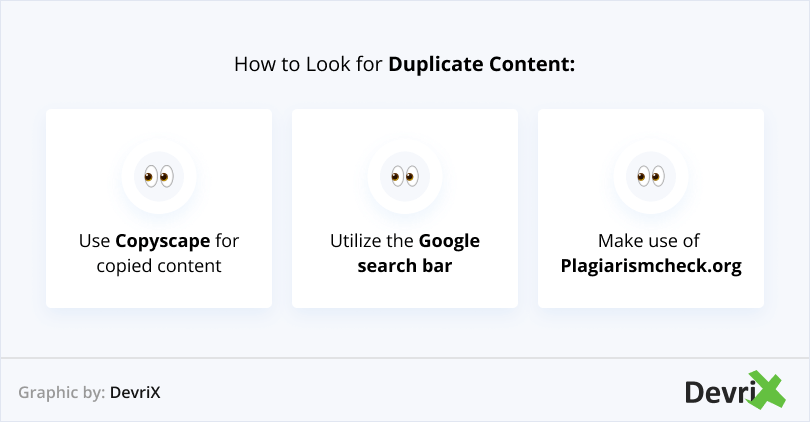
- Take parts from your content and put them in the search bar. Put quotation marks at the beginning and end of the search query. This way, you are telling Google that you are looking for results with the exact same wording. If anything aside from your own webpage comes up, then that means that somebody else has copied your content.
- Go on Copyscape and see if you can find duplicate content on another domain. This tool can determine if your content has been taken from somewhere else.
- Another tool that you can use is Siteliner. It automatically checks your website once a month to make sure that there is no duplicate content.
- Plagiarismcheck.org is a paid tool that detects paraphrased text and copied content.
Regularly checking for duplicate content is a crucial aspect of optimizing your website for search engines. It should be practiced regularly to make sure that you are getting the most out of your SEO efforts.
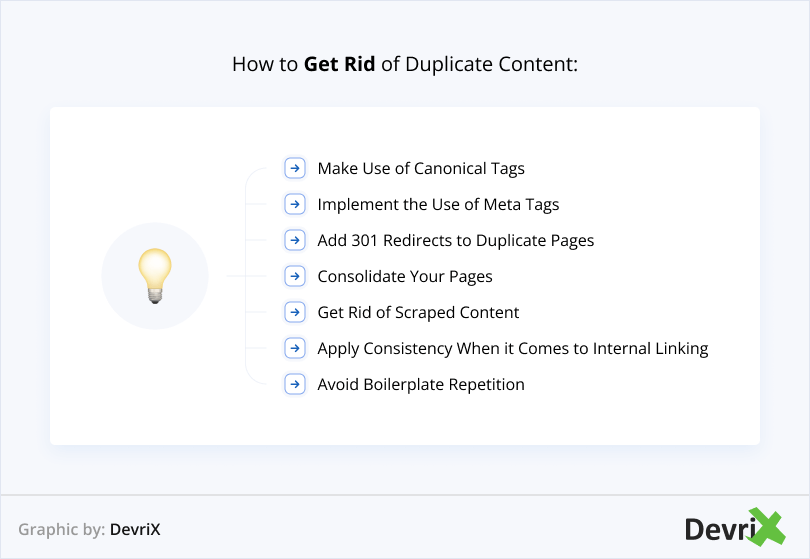
We’ve listed a couple of things that you can do to get rid of duplicate content and pages:
1. Implement Canonical Tags
Canonical tags are a simple way to let Google know which pages you are trying to rank for with certain keywords on their search engine. For example, you have pages A, B, and C, and you are using similar keywords and ideas for all these pages. However, Google can get confused as to which pages it should rank since the pages basically contain the same thing.
To avoid this problem, it is vital to choose just one page that you want to rank for. Let’s say page A is the page that you’ve chosen. You can put canonical tags on each page but pages B and C will point to page A. Pages B and C are still indexed, but now Google is aware that page A is the authority.
Pages with the same keyword focus and content can compete with each other, which is why implementing canonical tags is a must. Without it, your pages wouldn’t rank on the first page of Google.
WordPress plugins such as Yoast offer canonical tag functionalities that are useful if you have several pages that use the same keyword and you are trying to avoid getting tagged with duplicate content and pages.
2. Use Meta Tags
Meta robot tags can be used if you want to prohibit certain pages from being indexed by Google. The “no index” meta robots tag will prevent Google and other search engines from showing these pages in search results.
However, you should be warned that using the meta robots tags will completely prevent duplicate WordPress pages from showing up on search engines. If you want the page/s to be indexed, then consider doing tips number one and three instead.

3. Utilize 301 Redirects
Implementing 301 redirects is one of the easiest ways to get rid of duplicate WordPress pages on your site. Adding it will help Google redirect the audience to the original page. This step is a must if you are reconstructing your website.
301 redirects can be performed on the webserver’s software such as IIS and Apache. It can also be done on server-side programming including JSP, PHP, ColdFusion, Perl, and ASP/.net. To learn more about implementing 301 redirects, click here.
4. Consolidate Your Pages
If you do not want to do the three things that we have mentioned above, then consider compiling all of your similar content into one page. Here you could consider rewriting some of your duplicate WordPress pages that have the same idea and turn them into one long-form article. This will help Google recognize these pages and rank them based on the keywords that you have used.
5. Be Aware of Scraped Content
Content scraping is when third-party websites copy your content verbatim and then post it on their own. Always ask these sites to link the content back to your site so Google will know that yours is the original one. You can also request to have the copied content or page tagged with the “noindex tag” to prevent getting duplicate content.
6. Be Consistent With Internal Linking
Make sure that you are using the same URL when it comes to internal linking. Check what the canonical version of the domain is and be consistent with your internal links all throughout your content.
7. Pay Attention to Boilerplate Repetition
Avoid placing the same copyrighted text at the bottom of each webpage, as even this can be tagged as duplicate content.
You can, instead, put a summary of the text and link it to a separate page. This page should contain all of the important information about your copyrighted text. Consolidating your content into one page can help prevent duplicate content.
Avoiding Duplicate Content
Planning ahead and regularly maintaining your website is a good practice to prevent duplicate content. Always mark the content’s original source and let Google know which page you are trying to rank. Ensuring the uniqueness of your content is also a good way to steer clear of duplicate content.
You can also use canonical tags to indicate the preferred version of a web page. This can help search engines understand which version of a page to index and rank.
Taking the right measures to eliminate duplicate content should be based on how it was implemented. You might need to execute one or more tactics to let search engines know that your content is the one to rank. Feel free to take the steps that we have provided above and apply them to your website to rank higher on search engines.
Team DevriX
This article is crafted by DevriX's seasoned marketing team, boasting over four decades of collective expertise in crafting sophisticated marketing funnels, devising comprehensive content frameworks and pillars, implementing engaging email campaigns, and creating impactful social media content designed for scalability.
Our marketing experts specialize in the complete spectrum of inbound marketing strategies. As an accredited HubSpot Agency Partner and a Semrush Partner, we engage in meticulous research, blending our extensive experience with the unique insights of our highly skilled team.
We set benchmarks in content creation by incorporating cutting-edge marketing trends, leveraging in-depth industry research, and utilizing state-of-the-art AI tools for data segmentation and captivating content hooks. Our proficiency extends across a diverse range of sectors, including working with SMEs, Fortune 1000 companies, global B2B brands, major publishing entities, WooCommerce platforms, business directories, and affiliate networks.



